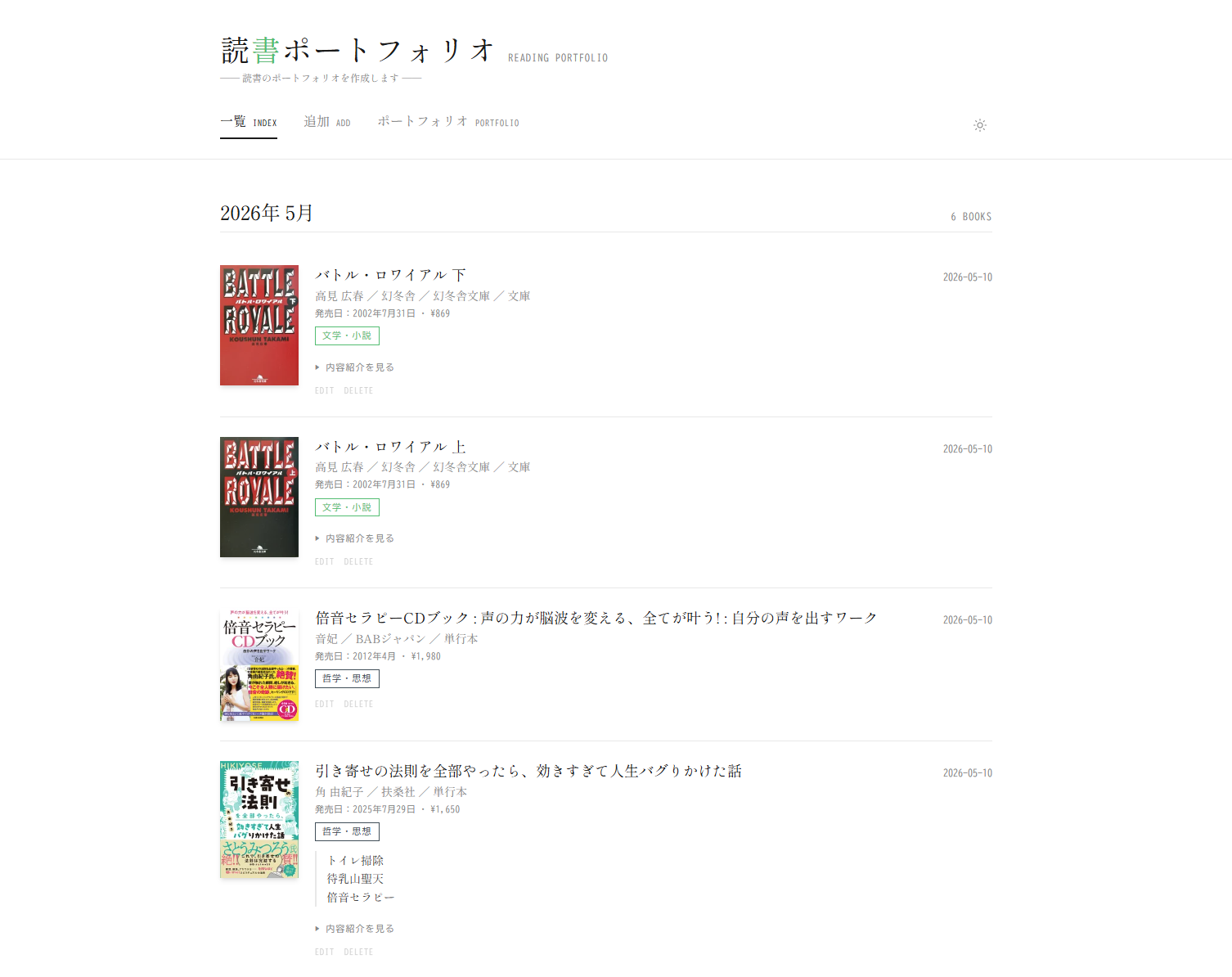
バランスよく本を読みたい。何ごとも分散投資したい。自分が読む本に偏りが出ていないか、一目でチェックしたい。それを投資信託のポートフォリオみたいに、円グラフで確認したいと思いました。
既存の読書アプリは色々あるのですが、「ジャンルの偏りを資産配分のように可視化する」ものが見当たらず・・。それなら自分でつくってみよう、と思い立って半日。書名もしくは ISBN を入れると、書誌情報・表紙画像・ジャンルが自動で取れて、読了日と感想を残せるアプリができあがりました。ひとまず本人専用です。
全体の構成と、開発の流れ
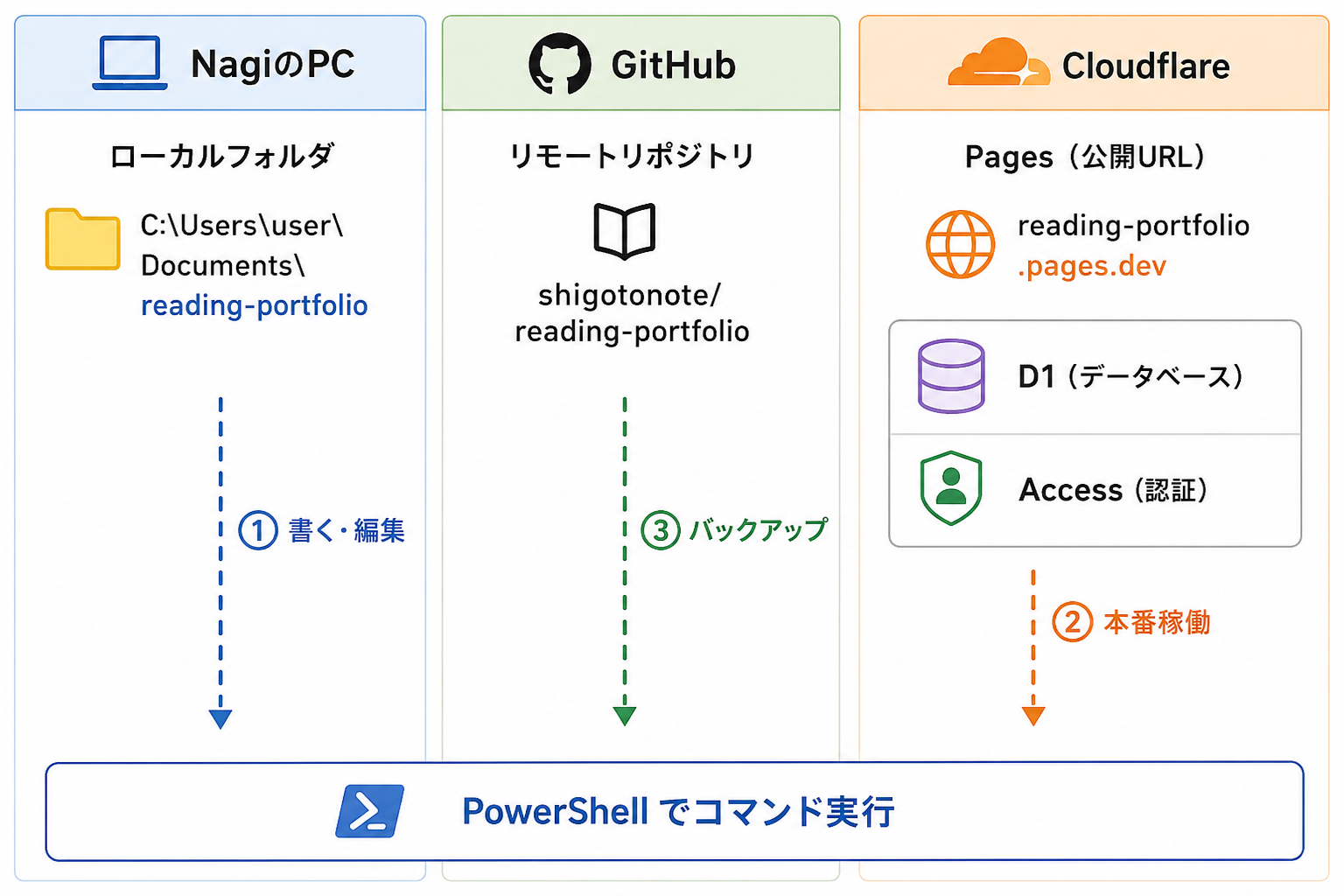
アプリには「読書ポートフォリオ」という名前を付けました。プロジェクトのフォルダ名や URL は、半角英数の reading-portfolio を使っています。
まず、自分が「どこで」「何を」操作しているのかを整理しておきます。今回の開発では、3 つの場所を使い分けていました。
| 場所 | 役割 |
|---|---|
| ローカル PC(C:\Users\user\Documents\reading-portfolio) | コードを書く・編集する場所 |
| Cloudflare Pages(reading-portfolio.pages.dev) | アプリが実際に動いている本番環境 |
| GitHub(shigotonote/reading-portfolio) | コードのバックアップと変更履歴管理 |
これらをつなぐのが PowerShell です。PowerShell から各種コマンドを叩いて、ローカルのコードを Cloudflare にアップロードしたり、GitHub にバックアップしたりしていました。
具体的には、PowerShell からこんな操作をしていました。
① コード変換と Cloudflare へのアップロード
npm run buildでブラウザが理解できる JavaScript に変換 →npx wrangler pages deploy distで Cloudflare に直接アップロード② Cloudflare データベース(D1)の操作
npx wrangler d1 execute reading-portfolio --remote --file=migrations/xxx.sqlでテーブル作成やデータ更新③ GitHub への同期
git add .→git commit -m "..."→git pushでバックアップ
ここで重要なのは、GitHub と Cloudflare Pages はまったく独立したサービスだということ。私の場合、ローカルから GitHub への push と、ローカルから Cloudflare へのデプロイを、別々に実行していました。
本来は GitHub と Cloudflare Pages を連携させて「git push するだけで自動デプロイ」という構成も組めますが、今回はシンプルに分離しています。
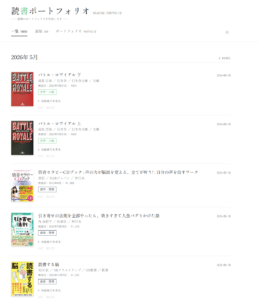
こうしてできあがったアプリの一覧画面はこんな感じです。月ごとに読んだ本が表紙画像つきで並びます。
仕様
つくったアプリの機能は次の通りです。
ISBN またはタイトルで本を検索(NDL サーチ → 楽天ブックス)
表紙画像・発売日・価格・内容紹介・楽天ジャンルを自動取得
楽天ジャンル ID から自分のカテゴリへ自動マッピング、手動上書きも可能
月ごとの一覧と、ジャンル別の円グラフ・月次バーチャート
感想の編集・削除 UI
ライト/ダークモード切替
Cloudflare Access で本人のメールアドレスのみアクセス可
技術スタック
| レイヤ | 採用 |
|---|---|
| フロント | React + Vite + TypeScript + Tailwind CSS |
| チャート | Recharts |
| バックエンド | Cloudflare Pages Functions(TypeScript) |
| DB | Cloudflare D1(SQLite、APAC リージョン) |
| 認証 | Cloudflare Access(Free プラン、メール OTP) |
| ソース管理 | GitHub(Private リポジトリ) |
| 書誌 API | 国立国会図書館サーチ + openBD + 楽天ブックス |
すべて無料枠で収まる構成にしました。Cloudflare Pages の無料枠は月 10 万リクエスト、D1 は月 500 万行読み取りまで無料なので、個人用途では十分に余裕があります。
書誌 API の選定
書誌情報をどこから取るかが、設計の最重要ポイントでした。検討した候補は次の通りです。
| API | 採否 | 判断理由 |
|---|---|---|
| NDL サーチ | 採用 | タイトル検索の網羅性が高い。RSS 形式で返ってくるので XML パーサが必要 |
| openBD | 採用 | ISBN から書誌詳細と C コードを取得。ただし新書系は欠落多い |
| 楽天ブックス | 採用 | 表紙画像・内容紹介・楽天ジャンル ID が取れる。アプリ ID のみで認証可 |
| Google Books | 不採用 | レート制限(429)が頻発。匿名共有プロジェクトが混雑 |
| NDL サムネイル | 不採用 | CloudFront で 403 を返される |
| Amazon PA-API | 不採用 | アソシエイト規約で自己購入禁止。本人専用ツールでは PA-API のアクセス権維持に必要な売上実績が確保できない |
結局、3 つの API を以下の役割で組み合わせました。
- NDL サーチ:タイトル → ISBN の検索
- openBD:ISBN → 書誌詳細と C コード
- 楽天ブックス:ISBN → 表紙画像・楽天ジャンル ID・レビュー情報
openBD でカバー画像が取れない(新書・文庫に多い)場合は、楽天ブックスへフォールバックする実装にしています。
楽天 API のハマりどころ
楽天ブックス API は、アプリ ID をクエリパラメータに含めるだけで叩けるシンプルな API なのですが、新規で発行したアプリ ID が想定通りに動かないという問題に遭遇しました。
新しい楽天ウェブサービスのアプリ登録フォームで「Web アプリケーション」タイプで発行した UUID 形式のアプリ ID(例:128f2a65-739e-4aa9-a1e5-d7d4c4f18096)で楽天ブックス API を叩くと、こうなります。
{"error_description":"specify valid applicationId","error":"wrong_parameter"}
調べたところ、UUID 形式のアプリ ID は OAuth 認証用の新しい系統で、楽天ブックス API のような従来型 API では使えない仕様でした。従来型で動くのは古い 20 桁数字形式のアプリ ID(例:1071547376319795108)のみです。
「API/バックエンドサービス」タイプで新規登録すれば 20 桁形式が発行されるかと思いきや、今度は「許可された IP アドレスを登録してください」という制約があり、Cloudflare Pages のような分散インフラでは特定の IP を指定できないので使えません。
別件で以前発行していた 20 桁形式のアプリ ID を流用することで解決しました。楽天規約上、同じアカウント内で複数用途に使うことは禁止されていません。
カテゴリ自動分類
本のジャンル分類には、楽天ブックスの booksGenreId を使いました。これは / 区切りの階層構造で返ってきます。
"booksGenreId": "001020008/001020007/001008011010/001008011001/001008001003"
001008 配下が「人文・思想・社会」、その下の 001008011 が「社会」、001008003 が「思想・哲学」というふうに枝分かれしています。
D1 にマッピングテーブルを作って、楽天ジャンル ID 前方一致で自分のカテゴリに振り分ける設計にしました。
CREATE TABLE rakuten_genre_mapping ( rakuten_prefix TEXT PRIMARY KEY, category_id INTEGER NOT NULL, display_order INTEGER DEFAULT 0, FOREIGN KEY (category_id) REFERENCES categories(id) );
カテゴリ解決の優先順位は次の通りです。
- 手動上書き(
reading_logs.category_idが NULL でない) - 楽天ジャンル ID(前方一致で最も具体的なものを優先)
- C コード(openBD 由来、3-4 桁目)
- 「その他」フォールバック
SQL の COALESCE で多段階に解決しています。
COALESCE(
l.category_id,
(SELECT g.category_id FROM rakuten_genre_mapping g
WHERE b.rakuten_genre_id IS NOT NULL
AND (b.rakuten_genre_id LIKE g.rakuten_prefix || '%'
OR b.rakuten_genre_id LIKE '%/' || g.rakuten_prefix || '%')
ORDER BY g.display_order ASC, length(g.rakuten_prefix) DESC
LIMIT 1),
(SELECT m.category_id FROM c_code_mapping m
WHERE m.c_code_prefix = substr(b.c_code, 3, 2)),
(SELECT id FROM categories WHERE name = 'その他' LIMIT 1)
)
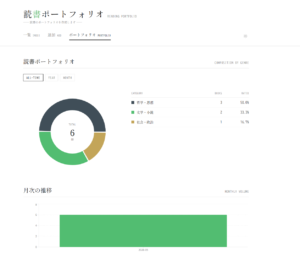
この仕組みのおかげで、本を登録すると自動的にジャンル分類され、ポートフォリオ画面では円グラフとしてジャンル比率が可視化されます。
ダークモード
CSS 変数で色を定義し、Tailwind を CSS 変数経由で参照する形にしました。これでクラス名(bg-paper、text-ink)はそのまま使いつつ、html.dark クラスで全体の色を切り替えられます。
:root {
--c-paper: 255 255 255;
--c-ink: 26 26 26;
--c-accent: 63 191 110;
}
html.dark {
--c-paper: 20 20 20;
--c-ink: 245 245 245;
--c-accent: 79 208 128;
}
Tailwind 側はこんな指定にします。
colors: {
paper: 'rgb(var(--c-paper) / <alpha-value>)',
ink: 'rgb(var(--c-ink) / <alpha-value>)',
accent: 'rgb(var(--c-accent) / <alpha-value>)',
}
テーマ状態は localStorage + prefers-color-scheme で管理しています。初回読み込み時のチラつき(FOUC)を防ぐため、index.html の <head> 内で同期的にクラスを当てるブートストラップスクリプトを入れました。
<script>
(function () {
var v = localStorage.getItem('theme');
var dark = v === 'dark' ? true
: v === 'light' ? false
: window.matchMedia('(prefers-color-scheme: dark)').matches;
if (dark) document.documentElement.classList.add('dark');
})();
</script>
Recharts のチャート色も getComputedStyle で CSS 変数から取得する形にして、テーマに追従させています。
本人専用化(Cloudflare Access)
世界に公開された URL のままだと、誰でもアクセスできてしまいます。本人専用に絞るため、Cloudflare Access の Free プラン(50 ユーザーまで無料)を使いました。
設定手順はこんな流れです。
- Cloudflare Zero Trust ダッシュボードで Free プランを選択
- チームドメイン(
xxx.cloudflareaccess.com)を発行 - Self-hosted アプリケーションを追加。ドメイン欄に
reading-portfolio.pages.dev - Identity Provider に One-time PIN(メール OTP)を選択
- Access ポリシーで Selector: Emails、Value: 自分のメールアドレスを指定、Action: Allow
これで、ブラウザで該当 URL にアクセスすると Cloudflare 側のログイン画面に飛ばされ、許可されたメールアドレスのみが OTP 認証を通過してアプリにアクセスできます。Session Duration を 1 ヶ月にしておけば、再ログインの煩わしさもありません。
GitHub へのバックアップ
コードを GitHub の Private リポジトリにバックアップしておきました。これは「本番環境」とは独立した「履歴管理とバックアップ」のための場所です。
PowerShell から、こんなコマンドで同期しています。
git status # 変更されたファイルを確認 git add . # 全ファイルをステージング git commit -m "..." # コミット(変更を確定) git push # GitHub に送信
これにより、ローカル PC が壊れても、GitHub から git clone すれば全コードを復元できます。今回は wrangler.toml(Cloudflare の設定ファイル)に楽天アプリ ID と D1 データベース ID が書かれていますが、Private リポジトリなので問題なしと判断しました。
.gitignore には以下を入れて、ローカル限定の自動生成物は除外しています。
node_modules dist .wrangler .dev.vars .DS_Store *.log *.tsbuildinfo
Cloudflare 環境変数の罠
楽天アプリ ID は機密性は高くないですが、コードに直接書くのは避けたいので、wrangler.toml の [vars] セクションに定義しました。
[vars] RAKUTEN_APP_ID = "1071547376319795108"
注意点として、wrangler.toml の [vars] で管理している環境変数は、Cloudflare ダッシュボードからは編集できません。ダッシュボード経由で編集できるのは「シークレット(暗号化された変数)」のみです。値を変えたいときは wrangler.toml を書き換えて再デプロイする必要があります。
NDL サーチの mediatype 指定
NDL サーチ API には mediatype というパラメータがあって、mediatype=1 を指定すれば書籍だけに絞り込めるはずなのですが、実際に指定すると検索結果が 0 件になることが多いです。データソースのインデックスとの相性らしいです。
仕方ないので mediatype は指定せず、すべての結果を取得した上で、ISBN を持つレコードをクライアント側で優先表示する処理にしました。並び順の制御もクライアント側でやっています。
// 完全一致 → ISBN持ち → 発行年降順
dedup.sort((a, b) => {
const aExact = a.title.replace(/\s+/g, '').toLowerCase() === queryNorm ? 1 : 0;
const bExact = b.title.replace(/\s+/g, '').toLowerCase() === queryNorm ? 1 : 0;
if (aExact !== bExact) return bExact - aExact;
if (a.isbn && !b.isbn) return -1;
if (!a.isbn && b.isbn) return 1;
return (b.pubdate_year ?? 0) - (a.pubdate_year ?? 0);
});
サムネイルの並列取得
NDL サーチの結果には書影 URL が含まれていません。表紙画像を出すには、各 ISBN について楽天ブックス API を別途叩く必要があります。
10 件並べたら 10 回の API 呼び出しになるので、シーケンシャルだと遅いです。Promise.all で並列化しました。
const withCovers = await Promise.all(
results.map(async (r) => {
if (!r.isbn) return r;
try {
const { cover_url } = await api.getCover(r.isbn);
return { ...r, cover_url };
} catch {
return r;
}
}),
);
並列だと最遅の 1 件に律速されますが、楽天 API は個人レベルで 1 件 0.3〜1 秒程度なので、10 件並列でも実質数秒で揃います。
アプリも、自給自足できる時代に
これまで何度かClaudeを使用してアプリを作成しています。「こういう機能がほしい」と自然言語で指示すれば実装が出てくるので、設計判断に集中できます。エラーが出たときも、エラーメッセージとログを共有すれば原因特定が速いです。
個人で使うツールを、自分で形にできる時代になりました。アプリは、誰かがつくってくれるのを待つもの、お金を払って使うもの、という時代は終わりを迎えようとしています。今は、必要なものを自分の手元でつくれる時代になりました。アプリの自給自足の時代が来ています。
自分でつくることが、一番の勉強になります。手を動かすことで初めて分かる感覚があります。「API を叩く」「データベースに保存する」「フロントエンドで表示する」といった概念が、抽象的な知識ではなく、実体のある手触りに変わっていく。これは既製品を使っているだけでは得られません。
自分でつくろう。
なんでも作れる時代になりました。

